
1. HBM 개요 및 특징
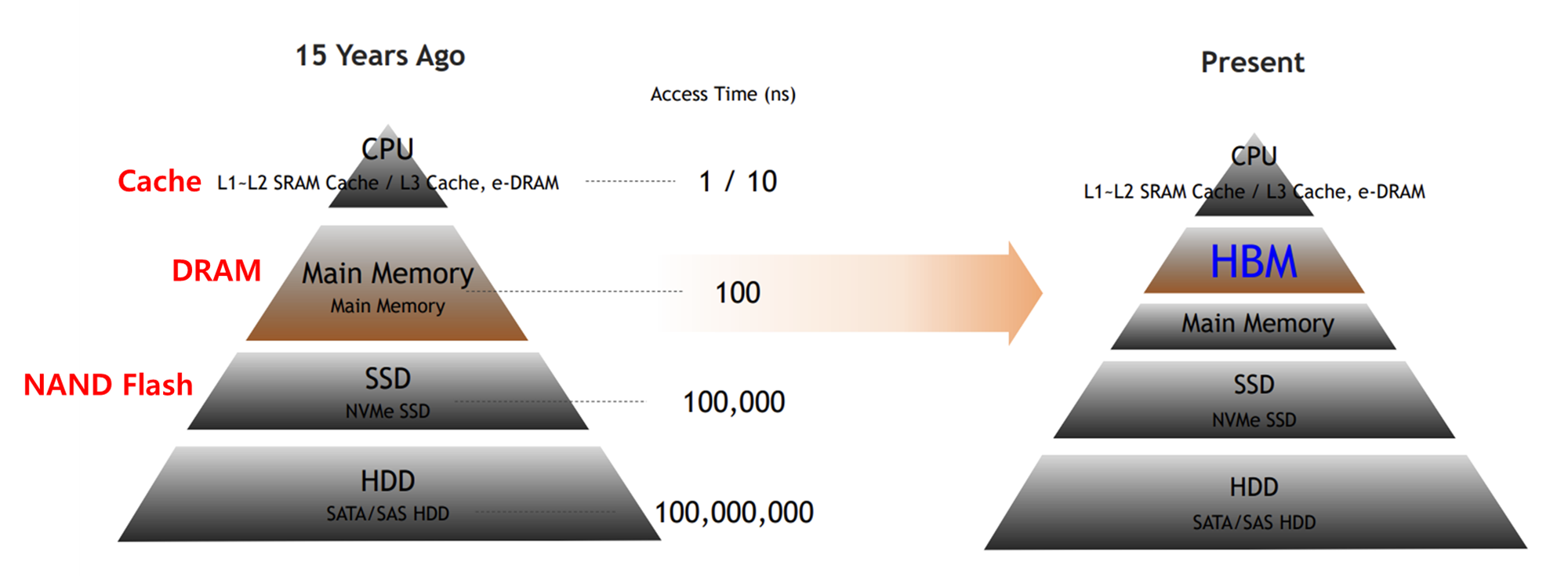
HBM (High Bandwidth Memory, 고대역폭 메모리)는 이름 그대로 한 번에 많은 양의 데이터를 동시에 전송할 수 있도록 넓은 대역폭을 가진 메모리입니다.
최신의 HBM은 DRAM 메모리 여러개를 수직으로 쌓아올린 적층 메모리 형태이며, 따라서 메모리 간 거리가 매우 짧아지고, 단위 면적당 용량이 크게 늘어난 것이 특징입니다.
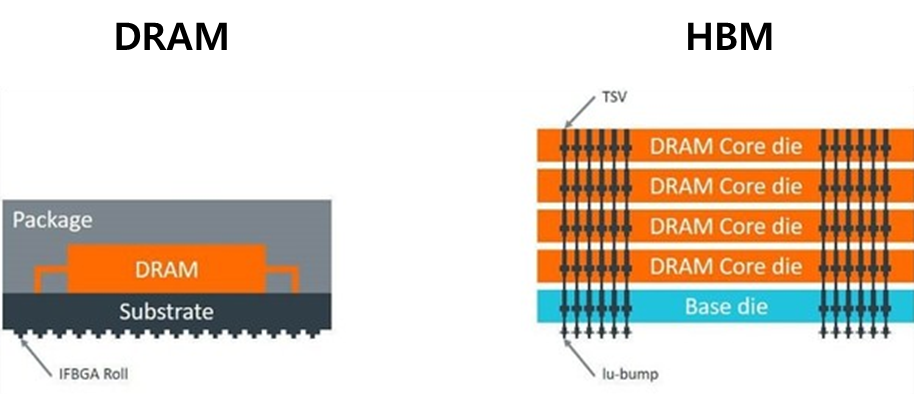
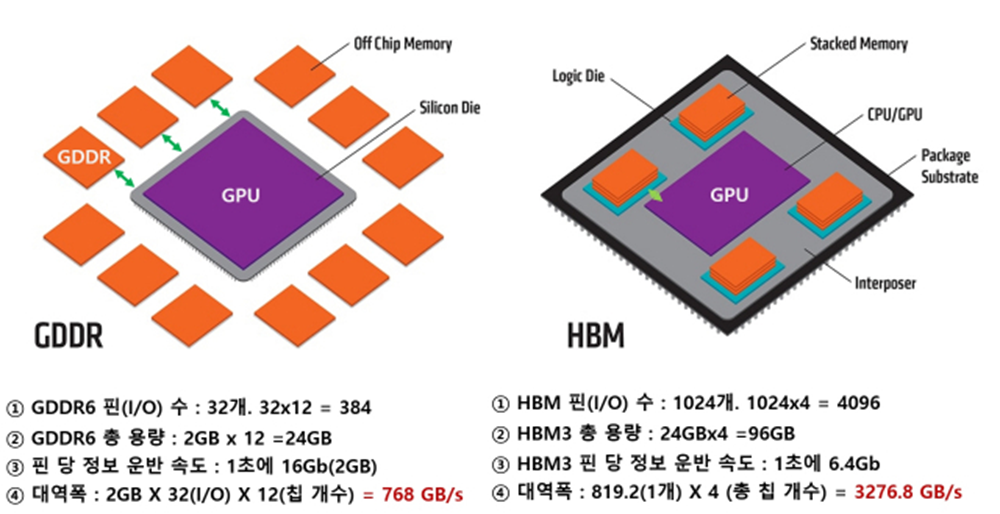
기존 그래픽 처리용 고대역폭 메모리(DRAM)로 사용되는 GDDR6(Graphic Double Data Rate DRAM)은 데이터 통로에 해당하는 I/O(Input/Output) Bus가 Wire Bondig 또는 Flip-Chip Bonding으로 연결되어 최대 32개(32bit)인 반면, 최신 HBM인 HBM3의 I/O Bus는 수직 적층된 메모리에 미세한 구멍을 여러개 뚫어서 연결해 (TSV) 현재 최대 1024개(1024bit)의 통로를 갖고 있습니다.
즉, 기존 GDDR 메모리의 경우 32차선 도로였다면, HBM의 경우 1024차선의 고속도로인 셈입니다.
여기에 기존 GDDR 메모리 한개의 용량은 2GB인 반면, HBM은 2GB 메모리 Die를 여러개 쌓아올리기 때문에 용량도 크게 늘어나게 됩니다.
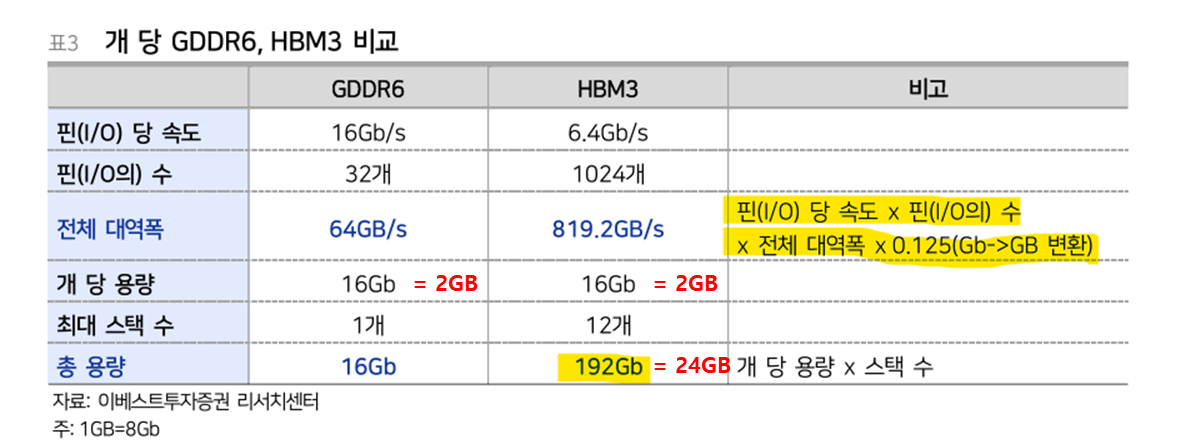
I/O 당 속도는 기존 GDDR6의 속도가 HBM 대비 2~3배 빠르지만, HBM의 I/O 개수가 크게 늘어나면서 단위 시간당 전체 대역폭은 HBM이 GDDR6 대비 약 12.8배 빠릅니다.
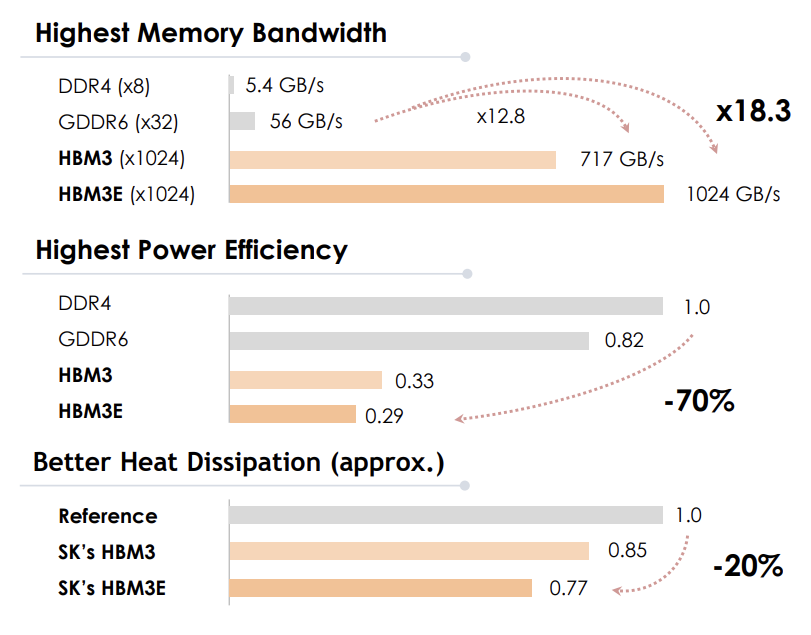
GDDR의 경우 GPU 주변에 총 12개의 메모리 유닛이 배치되어 총 384개의 I/O Bus, 24GB의 용량, 768GB/s의 대역폭을 가지는 반면, HBM의 경우 GPU 주변에 총 4개가 배치되어 총 4096개의 I/O Bus, 96GB의 용량, 3276.8GB/s의 대역폭을 가지기 때문에 약 4배의 용량 및 속도 차이를 보여줍니다.
2. HBM의 필요성
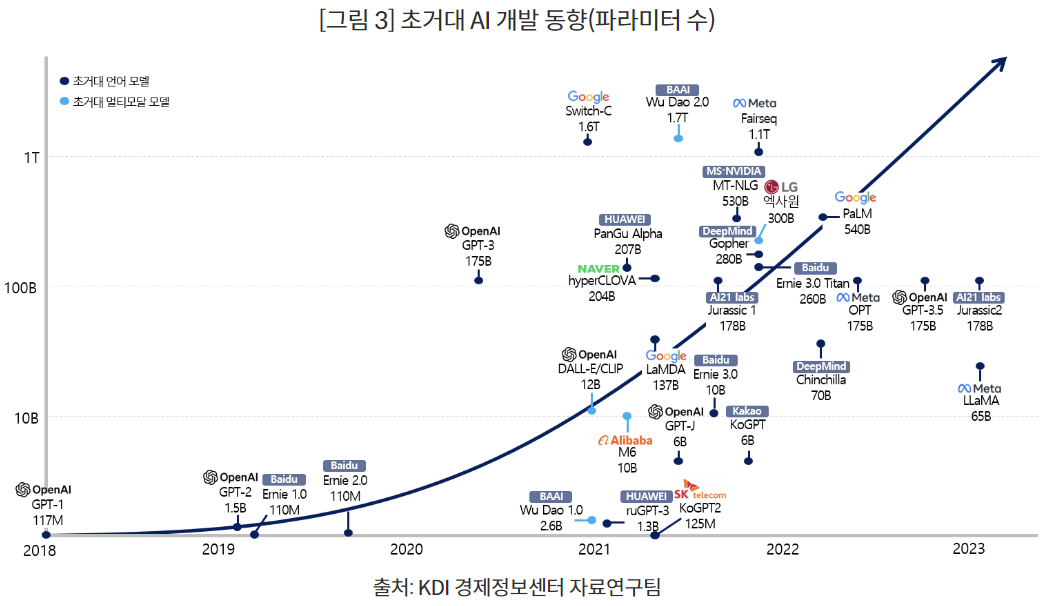
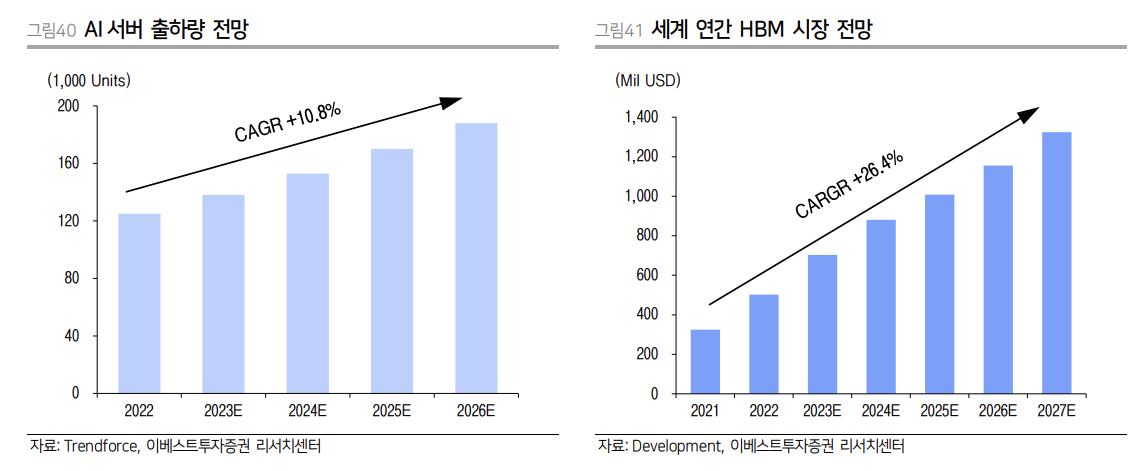
2022년, AI의 게임체인저인 ChatGPT, DALL-E, BARD 등 초거대 AI가 나타나면서 이들 AI 모델이 갖고 있는 대규모 파라미터(매개변수)를 학습 및 연산하기 위한 AI 서버 수요가 크게 증가하고 있습니다.
AI 모델은 어떤 인풋값에 대해 특정한 아웃풋값을 내뱉을 수 있도록 하는 거대한 비선형 함수(방정식)라고 보면 되는데, 파라미터란 이 거대한 비선형 함수의 해(미지수)라고 보면 됩니다.
즉, AI 모델을 학습시킨다는 것은 이 거대한 비선형 함수의 파라미터 값들을 찾는 것을 말합니다.
따라서 AI모델의 파라미터가 클수록 함수의 복잡도와 크기가 커지는 것이며, 더 많은 변수들에 대한 답을 연산할 수 있는, 하나의 성능 지표라고 볼 수 있습니다.
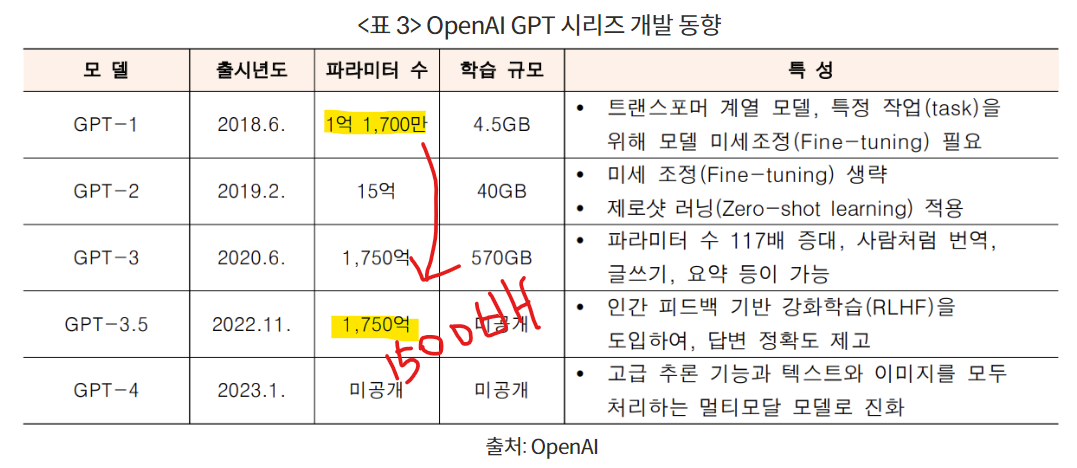
최근에 나온 ChatGPT와 같은 초거대 AI 모델의 특징은 어마어마한 양의 데이터를 학습해 범용성을 높였다는 것이며, 이를 통해 Few-Shot 학습, Zero-Shot 학습 등 모델의 재훈련 없이 새로운 예시를 조금만 넣어줘도 새로운 정보에 대한 학습이 가능하다는 점 입니다.
이를 통해 수많은 AI 서비스가 쏟아져나오고 있으며, 이를 위한 AI 서버 수요가 증가하고 있습니다.
이들 AI 서버는 기존 CPU가 처리하던 복잡한 계산의 순차처리 방식이 아니라, 대규모의 AI 모델 파라미터 및 학습 데이터를 병렬로 빠르게 처리할 수 있는 GPU가 필수적입니다.
또한 이러한 대용량 데이터를 메모리에서 GPU로 빠르게 전송하기 위한 기술도 필요했습니다.
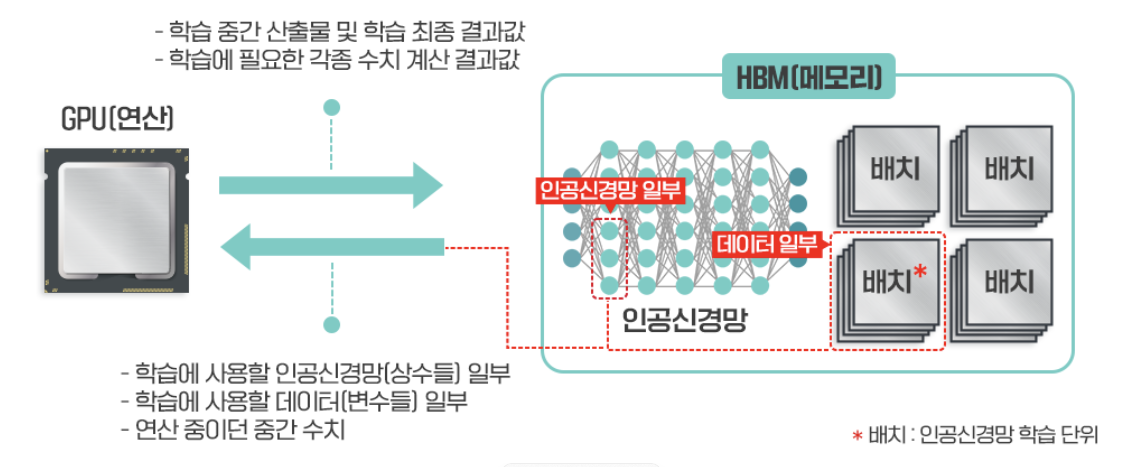
AI 모델의 파라미터 및
학습 데이터 규모의 급증에 따라
메모리-GPU 간
데이터 전송 병목현상 해소 필요
→ HBM!
그러나 기존의 GDDR DRAM의 경우 데이터를 전송할 수 있는 I/O Bus 개수가 적어서 GPU로 데이터를 전송하는 데에 병목현상이 발생하게 됩니다.
따라서 GPU 하나당 필요로하는 GDDR DRAM의 개수가 증가하게되고, 이는 더 많은 비용과 전력소모로 이어지게 됩니다.
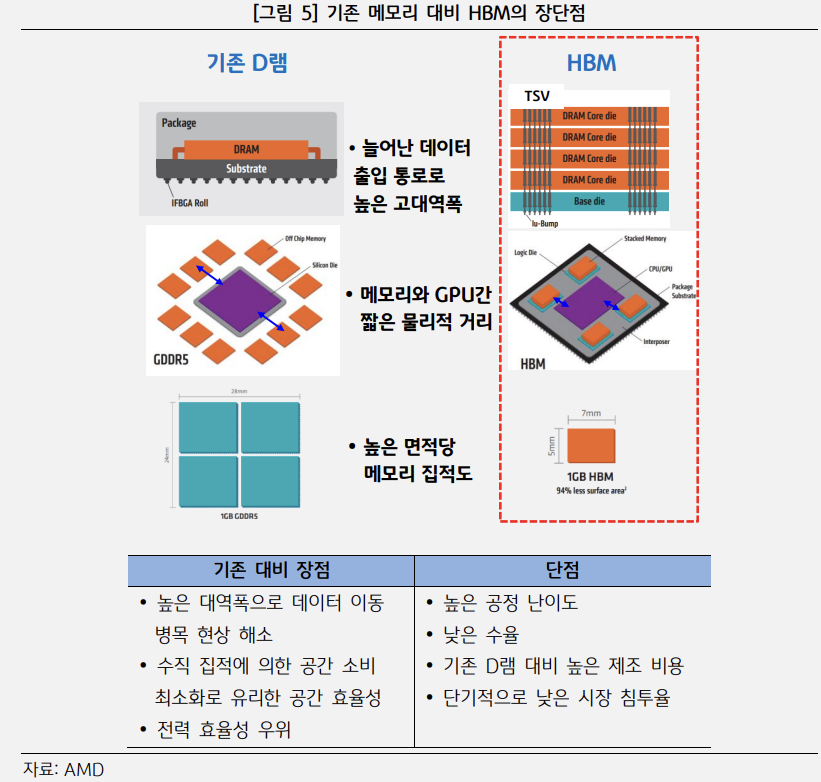
이에 반해 HBM은 기존 DRAM 대비 대역폭이 크게 증가하면서 GPU로 데이터를 전송하는데 발생하는 병목현상을 줄일 수 있고, 그에 따른 적력소모량도 감소하게 됩니다.
또한 메모리가 수직으로 쌓여있는 적층구조 특성상 면적을 줄일 수 있어 공간효율이 높아지게 되어 전체적인 비용 감소로 이어집니다.
결국 HBM이 필요한 이유는 대규모, 대용량의 데이터 및 AI 모델 파라미터를 동시 처리하는데에 필요한 AI 서버 인프라 비용을 줄이기 위함입니다.
이는 HBM 성능만의 개선으로 이루어지지 않고, GPU 등의 로직 반도체와의 데이터 전송 거리를 줄이고 전체적인 반도체 기판의 설계 효율 및 전력 효율등을 잡기 위한 첨단 패키징 기술 발전으로 이어지게 됩니다.
댓글